3.1 Pharmaceutical Treatment of PTSD & Adverse Effects on Suicidal Behavior
3.1.1 Competencies
Modules: 1 (Importing/Reading Data); 4 (Pandas Intro); 5 (Relational Data/Data Merging); 6 (Data Cleaning); Assorted Classification Modules
Competencies: Pandas (general); Data merging; Matplotlib/Visualization (basic, general); Cleaning string data; Cleaning inconsistently coded data; Sci-kit learn; Model fitting and cross-validation; Various possible classification model algorithms
3.1.2 Materials/Data
The below links lead to comma-delimited datasets to be used for the below assignment. Simply save the linked web pages (as csv files) once loaded.
3.1.3 Introduction
The present use case uses a simulated data set of patients with PTSD and suicidal-ideation or suicidal-related behavior (SRB) outcome data. This data and use case are inspired by the work of Noah Delapaz and William Hor under Dr. Lirong Wang related to pharmaceutical treatment of PTSD and related, adverse suicidal ideation. In this use case, you will first be given a large list of patients and previous ICD-9 and ICD-10 diagnoses, within which you will identify a patient sample of interest with a diagnosis of PTSD (as if you were identifying a study sample in the early stages of a research project).
After identifying your study sample of interest, you will use patient outcome and medication data to assess the effects of common PTSD-treatments on later diagnosis of PTSD and/or SRB. Steps will include data cleaning, exploratory data analysis, and model-building and evaluation as you work with this use case.
3.1.4 “Cohort Identification”
- The dataset
PossiblePatients_ICD.csvcontains a list of ~1,000 patients from a hypothetical electronic health record registry with various ICD-9 and ICD-10 diagnosis codes. We want to identify adult patients (18+) with a diagnosis of post-traumatic stress disorder. We will use the codes of309.81,F43.10,F43.11,F43.12to identify our diagnosis of interest. How many patients do you find in this data set that are eligible for your research study (i.e that meet this criteria)?
3.1.5 Tasks
3.1.5.1 Data Cleaning & Exploratory Analysis
Now we will work with the file PTSD_ResearchCohort.csv, a dataset of the 401 patients who were recruited and successfully completed our hypothetical study. A data dictionary is included below for reference:
Data Dictionary
| Variable | Description |
|---|---|
PTSD_Q1-PTSD_Q20 |
PTSD Questionnaire variables (see images below) describing presence of symptoms 6-months after study enrollment |
PHQ_Q9 |
Patient Health Questionnaire (or PHQ-9) question 9, which assessed presence of suicidality or ideation of suicide, also at 6-months after study enrollment |
Age |
“Continuous” (integer) age variable |
TimeFirstDiagnosis_Months |
Integer value. The number of months since the patient’s first diagnosis of PTSD |
AlcAbuse |
Binary variable, where 1 represents present alcohol abuse and 0 no alcohol abuse over the previous 6 months |
BeckAnxiety_BL |
Continuous measure ranging from 0-63, where higher values indicate greater presence and severity of anxiety symptoms |
IncomeCat |
Nominal categorical varible describing income category relative to the federal poverty line (described in the variable’s categories) |
SocialSupport |
Self-reported “social support”, with values ranging from 0 to 84, where higher values indicate higher self-reported social support |
PTSD_Rx |
Name of medication prescribed |
Import the research study data. We can assume that the patients in this data file are a sbuset of the eligible patients you identified above. How many patients that you identified in question 1 have available outcome data? How many were not recruited or have missing follow-up data (i.e. are not in this outcome data set)?
Using the PTSD questionnaire vairiables, crate a binary PTSD diagnosis/outcome variable. The following links include useful resources the PTSD checklist and respective variable coding and a guide to the scoring and diagnosis of PTSD using this checklist, with relevant information included below in Figures 1A and 1B.
| Figure 1A | Figure 1B |
|---|---|
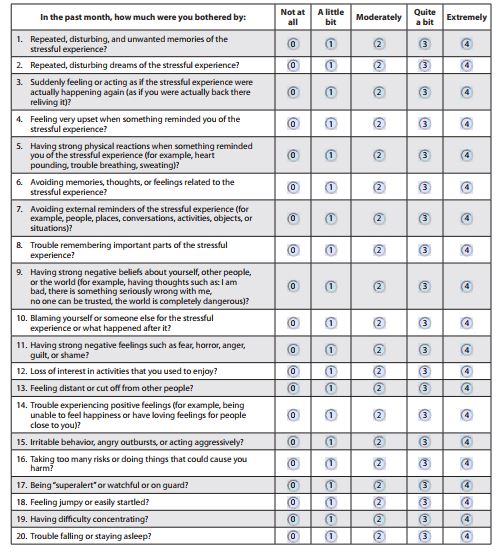 |
 |
- Create a variable that identifies suicidal ideation as present or absent:
- See the following article as a reference describing the PHQ9 questions. The 9th question in PHQ9 is often used to assess suicidality, with any values >1 (i.e. present symptom) indicating suicidal endorsement/ideation and is contained in your data set.
- Beyond the PTSD & PHQ variables, examine the other variables in the data set, and their descriptions in the Data Dictionary above. For any categorical variables, create indicator/dummy variables.
3.1.5.2 Build your model
Build a model on the training set predicting 6-month SRB and predicting 6-month PTSD diagnosis using the input features dentified in the data dictionary and that you’ve prepared in the data cleaning section above of age, time since earliest PTSD diagnosis, alcohol abuse, Beck Anxiety Inventory, alcohol abuse, income category, social support, and medication indicator variables. Select a modelling algorithm that allows you to examine feature importance.
Assess the fit of both your models
What medications are “important” in a predictive model of PTSD? Describe the relationship of each medication (generally) based on the level of evidence (say “high” or “low”) based on your interpretation of the results of your model.
What type of model did you fit and what specific measure did you use in 3a to assess importance? List two other types of classification models and how you would assess feature “importance” for these different models.